

Lab Data as a Service
and the Future of R&D On Demand
You design the biological dataset. The Ginkgo foundry generates the data. It’s a simple concept, but one with important implications for how we do biotech R&D. Today we’re talking about Lab Data as a Service.
Transcript
A biotech R&D project requires many different kinds of operations.
Let's say you're engineering a biologic, maybe it's an antibody, for a particular therapeutic target. There's a design stage. You're probably looking at AI for protein design and feeling pretty excited about it. Then you've got to build a library of candidates. That means synthesizing all the relevant DNA and transforming it into a cell line that will make your antibodies. After expression comes purification. Then some kind of performance assay - a test that will check if your designer antibodies are actually hitting their desired target.
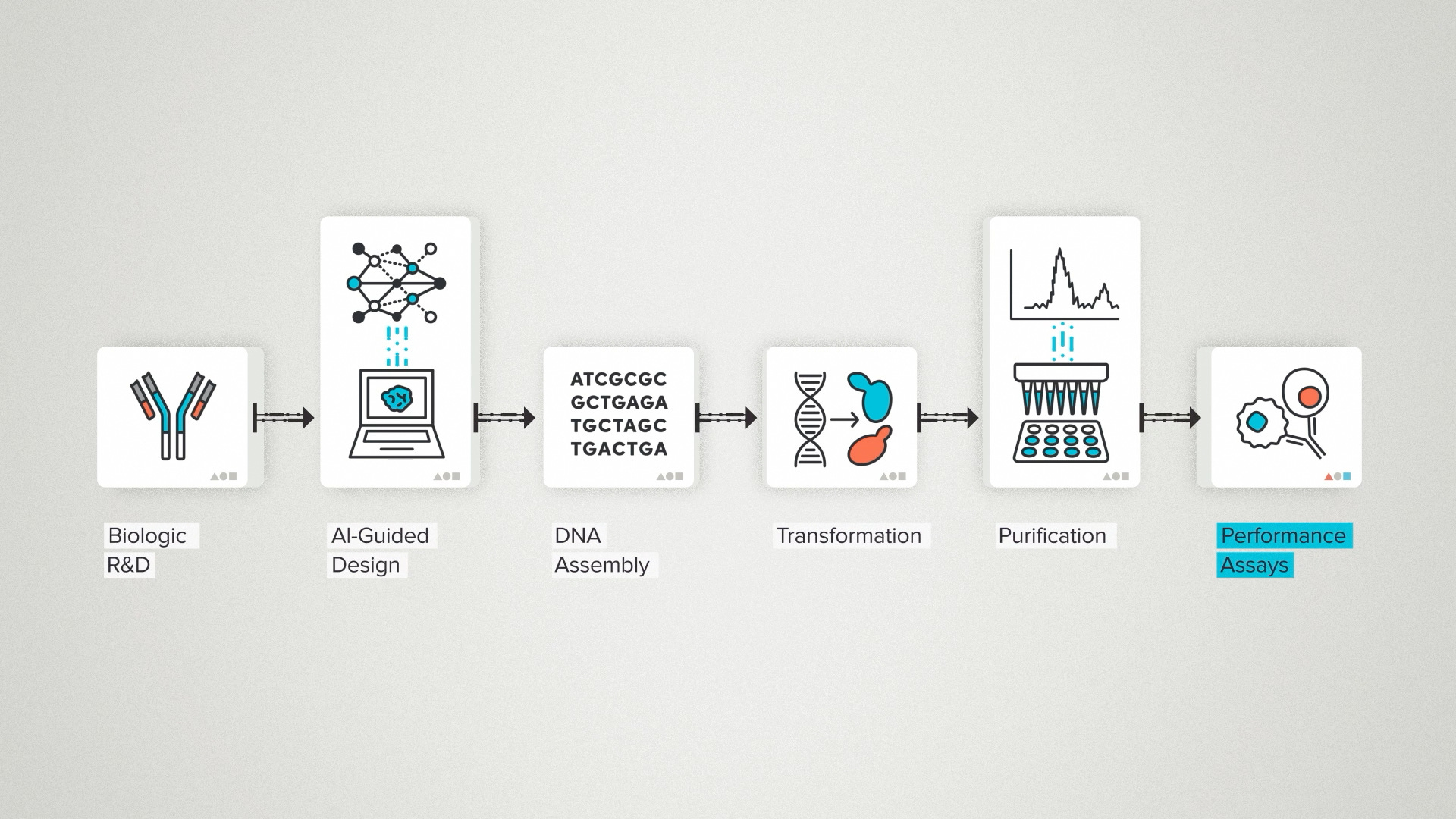
These days, you can usually find some good binders. But that's only the beginning. A good antibody drug needs to be specific, to be stable, to express well during manufacturing and so on. A whole set of other tests meant to de-risk clinical translation that are sometimes called developability assays.

I'm using this example, not just because Ginkgo offers antibody developability services. (Although we do - so, you know - call me1). But to show a concrete example of the many operations of an R&D project. Some of these steps are unique. Your antibody's target is going to be unique, so the binding assay has to be customized. But many of these steps are highly standardized across many R&D projects. DNA synthesis. Protein expression. Protein stability assays.
At Ginkgo, we call these standardized components foundry services. When we do R&D projects for our partners, we design them around our service capabilities. It offers a technical advantage, because lab operations get better with scale. We transform a lot of DNA. We purify a lot of proteins. So we can invest in the automation infrastructure that makes those things efficient. It also offers a conceptual advantage, simplifying the process of designing an R&D project. Our organism engineers don't need to track every technical detail of every service they call, so they can focus on the big picture.
Now, with Lab Data as a Service, we're offering our customers closer access to these services. Before, we only sold complete R&D projects, and only Ginkgo organism engineers could call data from the foundry. But as certain services get more standardized and more efficient with scale, it makes sense to open up those services to more external developers. Building biology like this has long been a dream of mine. So, I want to take a minute to explain why it feels so important.
If you're not in biotech, this concept might seem kind of obvious. Regular tech has been working like this for decades. Of course complex projects are built from services. Of course one application should be able to call data from another application through a seamless interface. But in biotech, the concept usually feels more glorious and far away.
If you've worked in a lab at any time in the last 40 years, you've had this conversation:
"Someday we're all just going to design experiments on computers. We'll be hanging out by the pool in Boca Raton, sipping a piña colada, while all the physical experiments happen in a big automated lab somewhere."

And you've also heard this one too:
"Umm actually automation will never replace human biologists because biology is too complex. Innovation requires doing experiments that have never been done before which, by definition, can't be standardized or scaled."

And I get it. I'm sympathetic to both of these points of view. I'm probably more sympathetic to the piña colada guy, if I'm being honest. But there's plenty of room for nuance here. You don't have to bow down to the robot overlords. But you also don't have to pipette 10,000 wells by hand.
One lesson that I'm learning from watching the development of Lab Data as a Service is that we can be thoughtful about pulling out those pieces of the biotech R&D process that benefit most from automation and scale. For some operations, it's super easy to plug in one service module.
Our first two offerings are enzyme performance and antibody developability. On the enzyme side, you can give us a set of enzyme sequences: 100, 1000 or more. We'll synthesize the DNA, produce the enzymes, and assay them for things you probably care about: activity, specificity, optimal pH, salt tolerance, stuff like that.

On the antibody side, it's the same idea. You give us the sequences for your antibody library. We'll give you the binding affinity, expression level or thermostability. Standard pricing. Terms and conditions apply, of course, but basically it's you design the library, we deliver the results.
I think the service model is the future of biotech R&D. And if you're looking to incorporate more services, this is what I'm seeing that makes it work.
1) They're Data in / Data out. If we're going to live the dream of designing DNA on the beach, we'll need services that accept digital inputs like DNA sequences and not physical inputs like, for example, cell lines.
2) They can be (mostly) standardized. Both enzymes and antibodies need some custom assays, but most of the work is the same regardless of the specific chemical reaction or target.
3) They need flexibility and scale. The most powerful thing about a service architecture is that the user can call as much or as little data as they need. At this particular moment, AI is transforming biotech and enzymes and antibody design is the avant garde. AI developers are thirsty for data and they're getting very creative in how they use it.
My dream for Lab Data as a Service is that the foundry is the backend serving all those developers. Call data from the foundry, put on your sunglasses, and take a sip of the beverage of your choice.
Lab Data as a Service on the Ginkgo Bioworks website