

Integrated Bioprocess Optimization: Gene, Host & Fermentation
I love it when a biological system can be broken down into simpler pieces. But biology doesn't care what I love. Today we're talking about what it takes to optimize many parts of a bioprocess all at once.
Transcript
Complex systems get easier to engineer when you approach them with design principles like modularity, abstraction and standardization. Mechanical engineers know this. Software developers know it.
Synthetic biology, my field, wants to bring those design principles to biology. It isn’t easy because biology doesn’t always show us the dotted lines that would set the boundaries of a module. Sometimes biology wants to be treated like a whole, with many moving pieces that have to be considered simultaneously.
The Ginkgo foundry is set up to handle hard problems that need an integrated approach - we call it cell engineering solutions. I want to walk through a case study to show how we can break a project into parts without losing sight of the whole.
Here’s the project I have in mind. A customer came to us because they wanted to make a food protein by precision fermentation. Our job was to provide an engineered microbe that makes this protein and the bioprocess conditions they can use to grow it.
This was a relatively challenging food protein because it needs to bind to a small-molecule cofactor to be functional. That means the microbe needs to make a lot of protein and a lot cofactor in order to get the final product. Other than that, this was a classic strain engineering project with a clear goal: make the most protein at the lowest cost.
So let’s break it down into simpler parts. How can we engineer this biology?
There's the gene for the protein itself. Most strain engineering projects focus on this part. The promoter that drives transcription and the codon choices that affect translation. The customer wanted the protein to be secreted from the cell to simplify downstream purification, so we needed an efficient secretion tag.
There's the microbial host organism. We work with yeast, fungi and different bacterial species. In this case we chose a yeast called Pichia because we know it's food safe and tends to be good for making the kind of protein that our customer wanted.
Then you’ve got to think about the host genotype: everything going on in the genome outside of the protein we're directly interested in. The protein production machinery inside the cell and the metabolic pathways that supply it with raw materials. Chaperones that stabilize your protein or proteases that might destabilize it.
And finally there's the fermentation conditions - the way your bioreactor is fed and grown at scale. What nutrient mix are you feeding the cells? What pH? What temperature?
If biology was perfectly modular, we could optimize each thing separately. One team for the host, one for the gene, one for the fermentation. Each team could focus on the simpler job of just getting their part right. But biology doesn’t like that.
The systems influence and depend on each other. Changing the fermentation temperature might mean you need a different mix of chaperones to help your protein fold. Changing the gene expression level might make the cells hungry for different nutrients, and so on.
This reality comes out in the first project meeting. The fermentation team will say: give me your best strains and I'll find the right conditions. The strain engineering team will say: give me the best conditions and I'll use them during strain development. How do you solve an integrated problem where no single part can be locked down independently?
One way to visualize our strategy is with a branching tree. We’re taking steps, one by one, into a space of growing possibilities. First, we choose a host microbe. There are relatively few options to start with. We introduce your protein and we make some choices about the expression system and the secretion system.
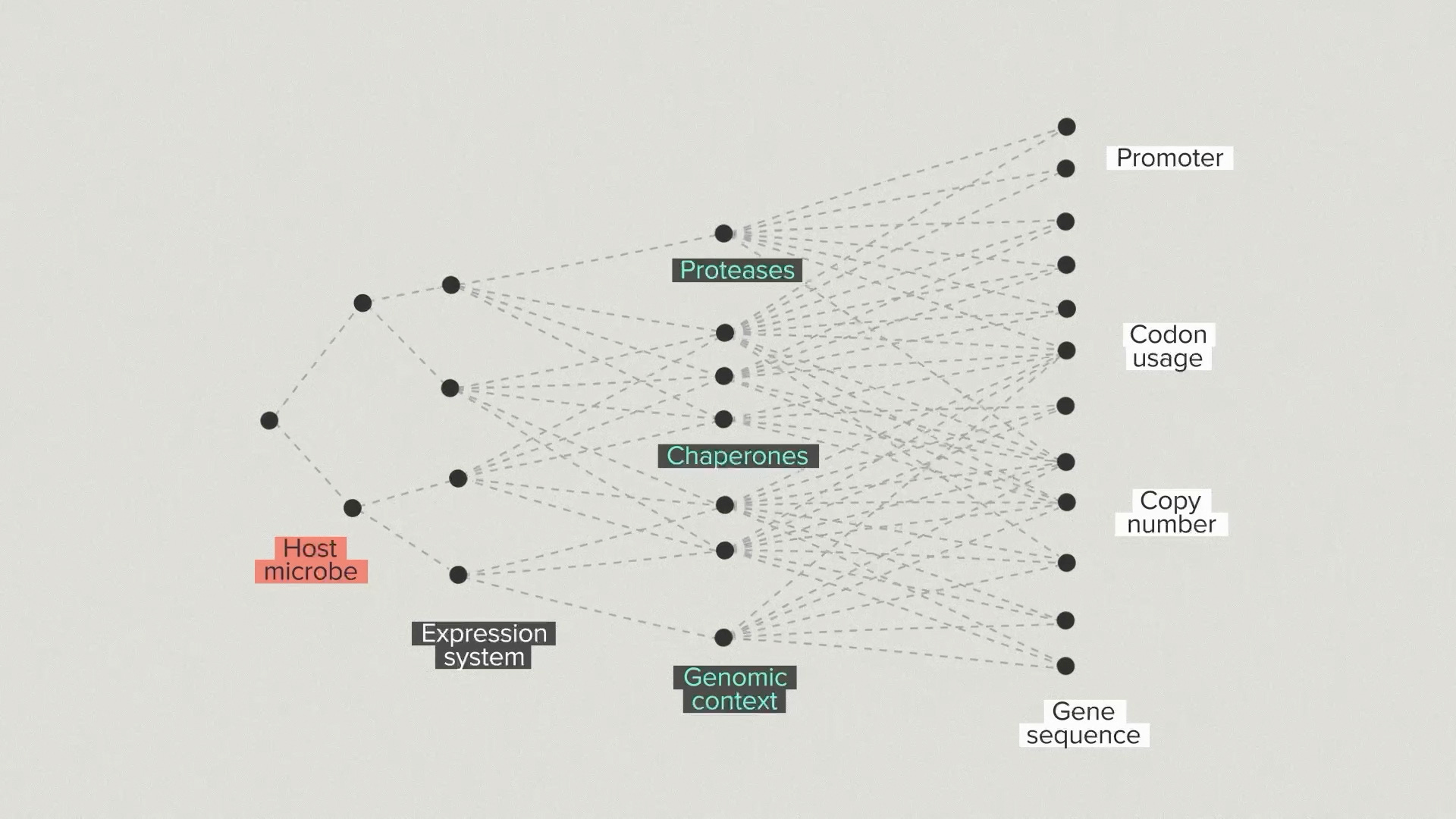
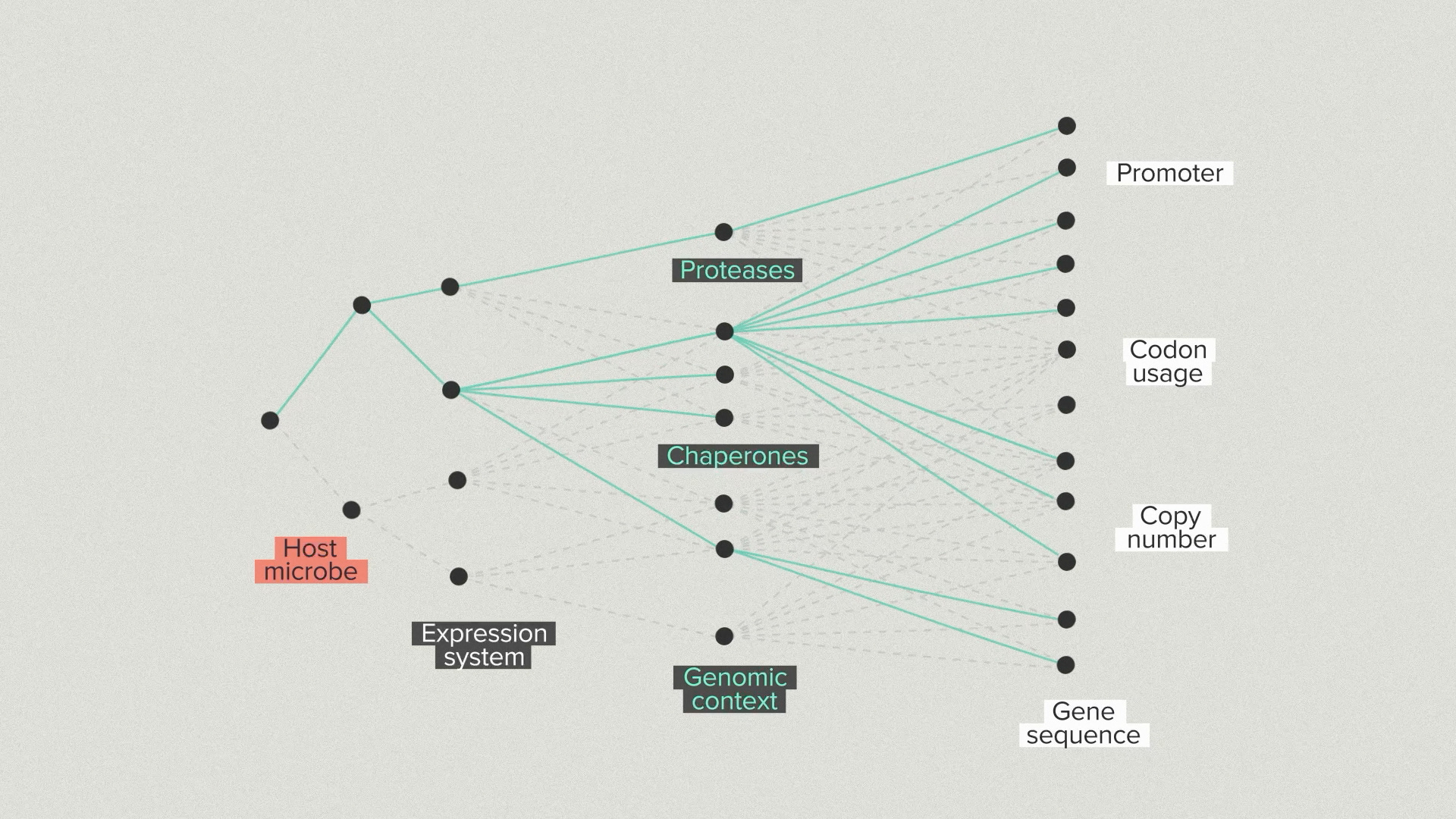
We go into the host and modify proteases, chaperones and other helper proteins. The number of possibilities is growing quickly now. We optimize the promoter, coding sequence and copy number of your protein. Because of the automation infrastructure at the Ginkgo foundry, we can test hundreds of configurations for the gene and host.
At each step, we select the best strains by validating them in benchtop reactors under realistic fermentation conditions. This is the ground truth for strain performance. It’s common for strains that do well in early development to perform poorly in bioreactors and vice versa. You need the high throughput screening to find the best strains and the bioreactor arrays to ensure that the top performers truly perform.
Every new branch optimizes for a different piece of the overall design. But, because we have the automation infrastructure to test thousands of designs, we don’t have to lock in the single best performer at each step. We can advance the top 3 strain backgrounds and the top 5 gene designs for each one. This diversity helps us avoid dead-end designs that work well in early stages but poorly later on.
For this food protein project, we tested more than 2000 different strain designs. We tested more than 400 different fermentation conditions at the benchtop scale. We went from 5 milligrams per liter of product to more than 5 grams per liter, all while supplying the protein with cofactor and keeping it functional.
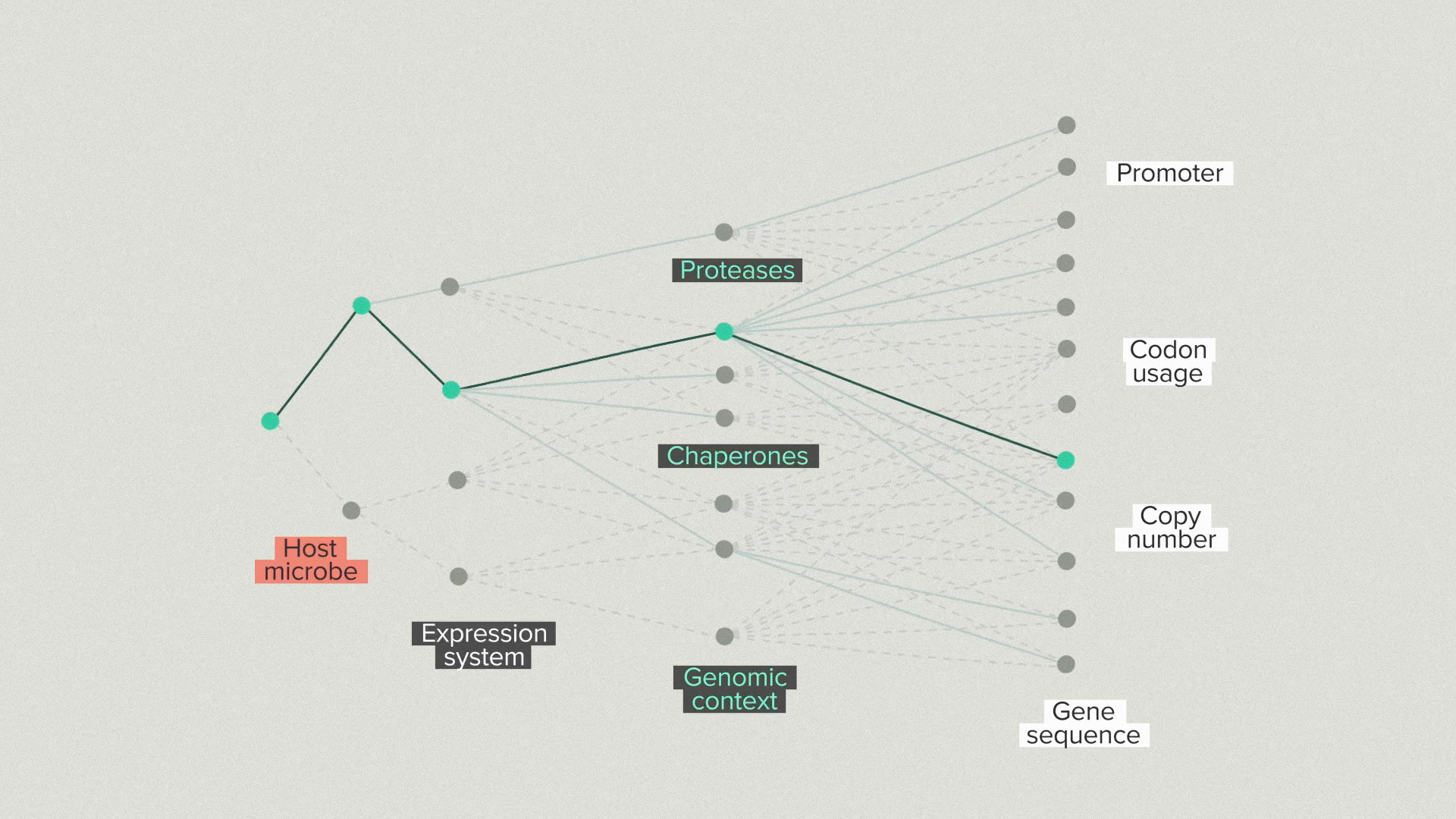
Most of the work in this project happened to be in finding the best secretion tag to get the protein out of the yeast efficiently. But there wasn’t a single kind of optimization doing most of the work. To get this 1000-fold improvement in productivity, you have to engineer the gene and the host and the bioprocess all together. What makes it work in the Ginkgo foundry is bringing the teams together around the complete cell engineering solution and giving them the automation capacity to take an integrated approach.